

vLLM enables 100-request concurrency on a single RTX A5000 for 7B LLMs (benchmark)
Benchmarking against HuggingFace Transformers, a meaningful baseline that practitioners universally understand

This benchmarking test evaluated the performance of vLLM against HuggingFace Transformers for serving the Discovery-Qwen2.5-7B model—a fine-tuned multilingual model designed for local business discovery. The tests were conducted on an NVIDIA RTX A5000 GPU with 24GB VRAM, measuring throughput, latency, memory efficiency, and scalability under various conditions. The results demonstrate that vLLM delivers transformative performance improvements that make the difference between a research prototype and a production-ready deployment.
Why Compare vLLM with HuggingFace Transformers?
HuggingFace Transformers is the de facto standard library for working with large language models. It provides an accessible, well-documented interface that most ML practitioners use for training, fine-tuning, and inference. The library has facilitated access to state-of-the-art models and serves as the foundation for countless AI applications.
However, HuggingFace was designed primarily as a research and development tool, not as a production inference engine optimized for serving real users at scale. When deploying LLMs in production—especially for applications serving multiple concurrent users—HuggingFace’s straightforward approach becomes a significant bottleneck.
Each request is processed sequentially
GPU memory is allocated statically regardless of actual usage
There’s no optimization for common patterns like shared system prompts.
These limitations compound quickly: a system that feels responsive during development becomes frustratingly slow under real-world load. This is precisely where vLLM enters the picture. vLLM is purpose-built for high-throughput LLM serving in production environments. It introduces several architectural innovations that fundamentally change how inference is performed:
PagedAttention for efficient memory management,
Continuous batching for handling concurrent requests dynamically, and
Prefix caching for scenarios with repeated prompt patterns.
The benchmark validates whether these claimed improvements translate to real-world performance gains using a fine-tuned Qwen 2.5 7B model. The following 5 tests were conducted :
[1] Throughput Comparison (Sequential vs Batched vs vLLM)
This is the fundamental comparison that answers the core question: how much faster is vLLM? We measured how many tokens per second each approach can generate when processing 20 identical prompts. Throughput directly translates to cost and user experience. Higher throughput means serving more users with the same hardware, reducing infrastructure costs, and delivering faster responses. In a production environment, throughput determines how many concurrent users your system can handle before response times become unacceptable.
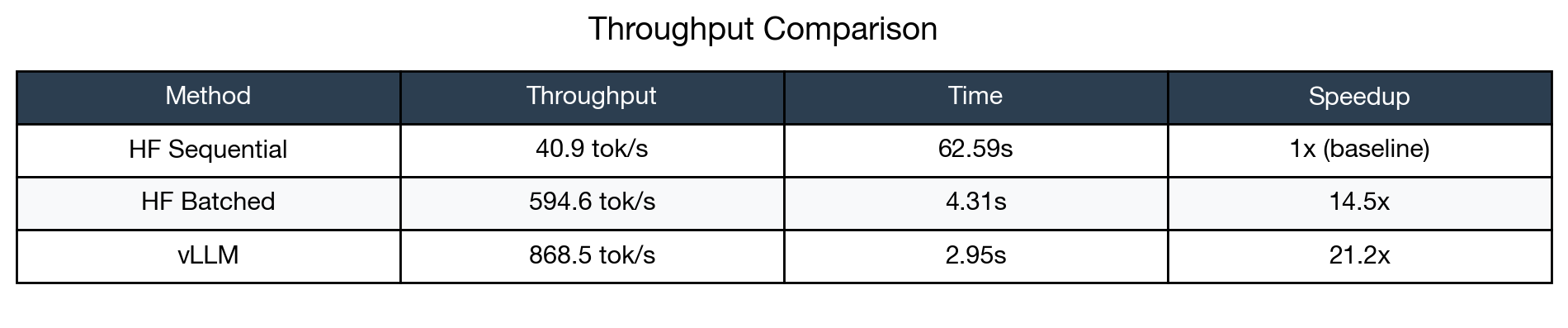
The results are striking and validate vLLM’s core value proposition. HuggingFace sequential processing—the default approach most developers use when following tutorials and documentation—achieved only 40.9 tokens per second. vLLM delivered 868.5 tokens per second, a 21.2x improvement. Even compared to HuggingFace’s batched inference (which requires additional code complexity and careful tuning), vLLM was 1.46x faster while being simpler to deploy and configure.
[2] Maximum Concurrent Sequences (KV Cache Efficiency)
This test pushed the system to handle increasing numbers of simultaneous requests (1, 10, 25, 50, 100, 150, 200) to identify the breaking point and understand scaling behaviour. Real-world applications don’t serve one user at a time. A local business assistant might hundreds of users querying simultaneously during peak hours. The ability to handle concurrent requests without crashing, running out of memory, or degrading severely determines whether the system is genuinely production-ready or merely a demo.
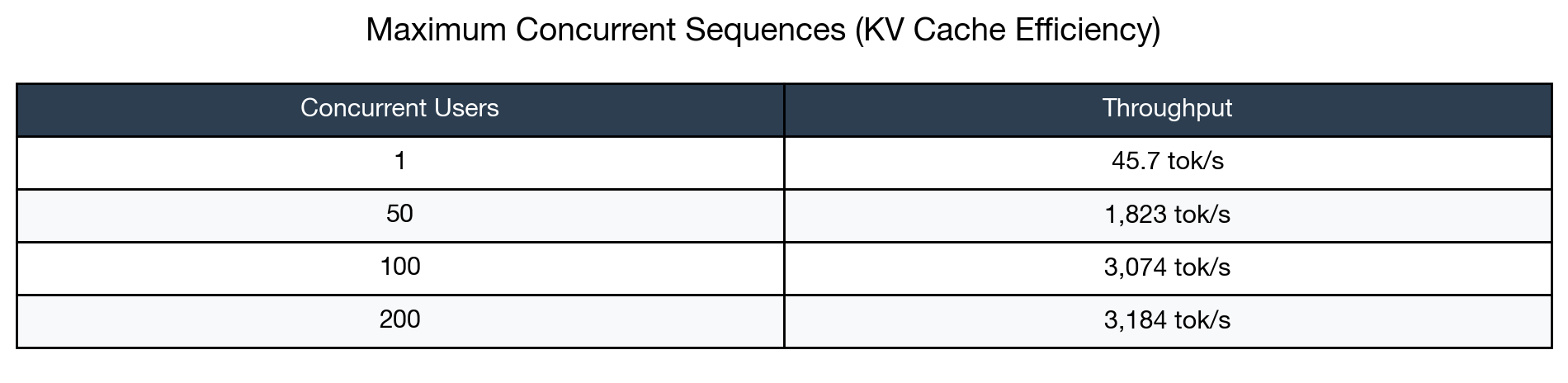
vLLM successfully handled all 200 concurrent sequences without failure. More importantly, throughput increased with concurrency—a counterintuitive result that demonstrates vLLM’s efficient batching strategy. The system achieved peak throughput of 3,184 tokens per second at maximum concurrency, nearly 70x faster than single-request HuggingFace performance. This remarkable scaling is possible because of PagedAttention, vLLM’s innovative memory management system. Traditional transformers allocate fixed memory blocks for each sequence’s key-value cache, leading to fragmentation and waste when sequences vary in length. PagedAttention allocates memory in small pages on-demand, similar to how operating systems manage virtual memory. This eliminates waste and allows significantly more sequences to run concurrently within the same GPU memory budget.
[3] Prefix Caching Impact
This test compared performance with and without prefix caching enabled, using 100 queries that shared a common system prompt—a scenario typical for chatbot and assistant applications. Production LLM applications typically use system prompts—detailed instructions that define the assistant’s behavior, personality, and constraints. For the fine-tuned model, every single query includes context about being a “helpful AI assistant for local business discovery ” that understands Hindi, English, Marathi, and Hinglish. Processing this identical prefix repeatedly for every user query wastes substantial computation.

Enabling prefix caching delivered a 32% speedup with zero code changes required. For the Discovery model’s specific use case—where every query shares the same system prompt defining its locality-focused, multilingual behavior—this optimization directly reduces latency and operational cost. Over thousands of daily queries, this improvement compounds into significant infrastructure savings and noticeably snappier user experiences.
[4] Concurrency Scaling
This test systematically measured how throughput and latency change as concurrent requests increase from 1 to 100. Understanding the scaling curve helps with capacity planning and setting realistic expectations. Does performance degrade gracefully under load, or does it collapse catastrophically? At what point do you need additional hardware?
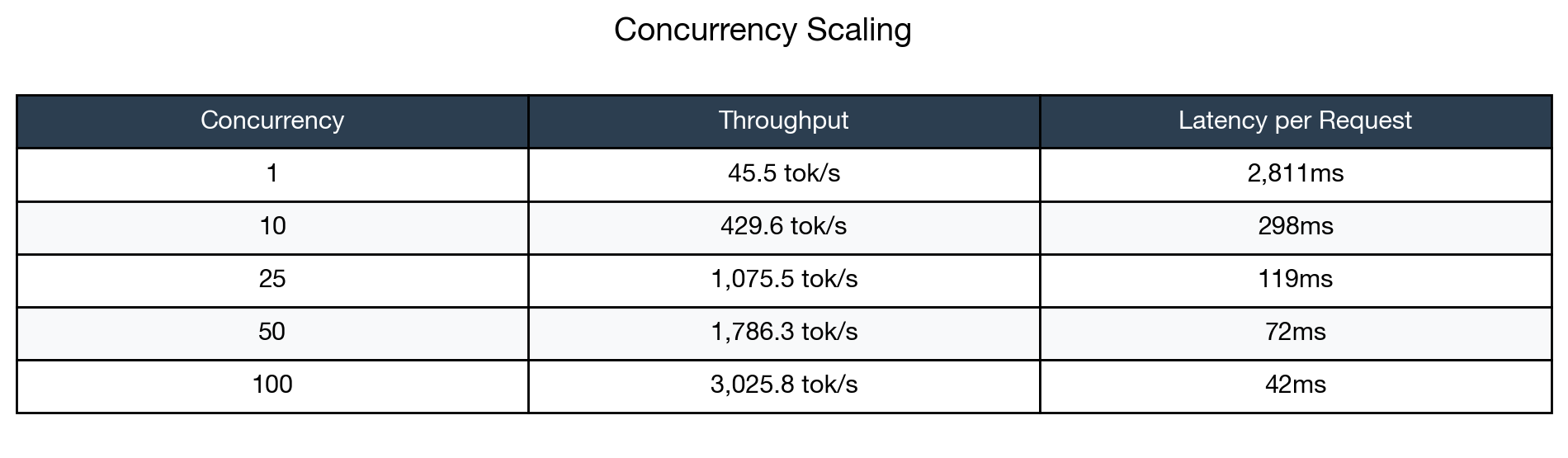
The results demonstrate excellent scaling characteristics that defy naive expectations. Throughput increased nearly linearly with concurrency up to about 50 users, then continued improving at a diminishing but still positive rate. Remarkably, per-request latency dropped from 2.8 seconds (single request) to an effective 42ms per request when processing 100 concurrent requests in 4.2 seconds total.
This counterintuitive behavior demonstrates continuous batching working exactly as designed: the GPU stays fully utilized processing multiple requests simultaneously, and individual requests benefit from efficient batched matrix operations.
[5] Chunked Prefill
This test evaluated chunked prefill performance with long-context prompts containing approximately 1,128 tokens each. Long prompts can cause latency spikes as the system must process the entire input before generating any output tokens. Chunked prefill addresses this by breaking prefill computation into smaller pieces, reducing time-to-first-token and improving perceived responsiveness.

For this moderate context length, chunked prefill showed minimal difference (~1%). This optimization becomes substantially more important with very long contexts exceeding 4,000 tokens. For typical Discovery model queries, which involve relatively short user questions, this feature is less critical but remains available when processing longer documents or conversation histories.

Conclusion
The benchmark comprehensively validates vLLM’s performance claim against HuggingFace Transformers.
For the fine-tuned Qwen2.5-7B model specifically, these results demonstrate that a single A5000 GPU can serve a substantial user base effectively. The prefix caching optimization aligns perfectly with the model’s architectural use case, where every query shares the same system prompt defining its local business assistant persona.
The choice to benchmark against HuggingFace Transformers provides a meaningful baseline that practitioners universally understand. vLLM isn’t incrementally better—it’s an order of magnitude faster, representing the difference between a functional prototype and a genuinely production-ready system capable of serving real users reliably.